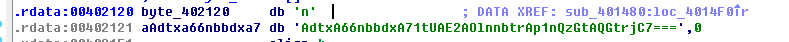Base-N算法及逆向初探 上次研究了CRC校验 ,这次来看一下Base-N系列的算法吧
在CTF的算法逆向中Base系列算是最常见的了,各种组合和变体,下面就具体来说说吧。
算法分析 Base64
Base64是一种基于64个可打印字符来表示二进制数据的表示方法。由于2^6=64,所以每6个比特为一个单元,对应某个可打印字符。3个字节有24个比特,对应于4个Base64单元,即3个字节可由4个可打印字符来表示。它可用来作为电子邮件的传输编码。在Base64中的可打印字符包括字母A-Z、a-z、数字0-9,这样共有62个字符,此外两个可打印符号在不同的系统中而不同。一些如uuencode的其他编码方法,和之后BinHex的版本使用不同的64字符集来代表6个二进制数字,但是不被称为Base64。
Base64常用于在通常处理文本数据的场合,表示、传输、存储一些二进制数据,包括MIME的电子邮件及XML的一些复杂数据。 —–维基百科 https://zh.wikipedia.org/wiki/Base64
编码规则
第一步,将每三个字节作为一组,一共是24个二进制位
如果要编码的字节数不能被3整除,最后会多出1个或2个字节,那么可以使用下面的方法进行处理:先使用0字节值在末尾补足,使其能够被3整除,然后再进行Base64的编码。在编码后的Base64文本后加上一个或两个=号,代表补足的字节数。也就是说,当最后剩余两个八位字节(2个byte)时,最后一个6位的Base64字节块有四位是0值,最后附加上两个等号;如果最后剩余一个八位字节(1个byte)时,最后一个6位的base字节块有两位是0值,最后附加一个等号。 参考下表:
C代码实现 #include <stdio.h> #include "string.h" #include "stdlib.h" const char base[] = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/="; static char find_pos(char ch); char *base64_encode(const char* data, int data_len,int *len); char *base64_decode(const char* data, int data_len,int *len); /** *找到ch在base中的位置 */ static char find_pos(char ch) { //the last position (the only) in base[] char *ptr = (char*)strrchr(base, ch); return (ptr - base); } /** *BASE64编码 */ char *base64_encode(const char* data, int data_len,int *len) { int prepare = 0; int ret_len; *len=0; int temp = 0; char *ret = NULL; char *f = NULL; int tmp = 0; char changed[4]; int i = 0; ret_len = data_len / 3; temp = data_len % 3; if (temp > 0) { ret_len += 1; } //最后一位以''结束 ret_len = ret_len*4 + 1; ret = (char *)malloc(ret_len); if ( ret == NULL) { printf("No enough memory.n"); exit(0); } memset(ret, 0, ret_len); f = ret; //tmp记录data中移动位置 while (tmp < data_len) { temp = 0; prepare = 0; memset(changed, 0, 4); while (temp < 3) { if (tmp >= data_len) { break; } //将data前8*3位移入prepare的低24位 prepare = ((prepare << 8) | (data[tmp] & 0xFF)); tmp++; temp++; } //将有效数据移到以prepare的第24位起始位置 prepare = (prepare<<((3-temp)*8)); for (i = 0; i < 4 ;i++ ) { //最后一位或两位 if (temp < i) { changed[i] = 0x40; } else { //24位数据 changed[i] = (prepare>>((3-i)*6)) & 0x3F; } *f = base[changed[i]]; f++; (*len)++; } } *f = ''; return ret; } /** *BASE64解码 */ char *base64_decode(const char *data, int data_len,int *len) { int ret_len = (data_len / 4) * 3+1; int equal_count = 0; char *ret = NULL; char *f = NULL; *len=0; int tmp = 0; int temp = 0; char need[3]; int prepare = 0; int i = 0; if (*(data + data_len - 1) == '=') { equal_count += 1; } if (*(data + data_len - 2) == '=') { equal_count += 1; } ret = (char *)malloc(ret_len); if (ret == NULL) { printf("No enough memory.n"); exit(0); } memset(ret, 0, ret_len); f = ret; while (tmp < (data_len - equal_count)) { temp = 0; prepare = 0; memset(need, 0, 4); while (temp < 4) { if (tmp >= (data_len - equal_count)) { break; } prepare = (prepare << 6) | (find_pos(data[tmp])); temp++; tmp++; } prepare = prepare << ((4-temp) * 6); for (i=0; i<3 ;i++ ) { if (i == temp) { break; } *f = (char)((prepare>>((2-i)*8)) & 0xFF); f++; (*len)++; } } *f = ''; if(data[data_len-1]=='=') { (*len)--; } /* while(*(--f)=='') { (*len)--; } */ return ret; } int main(){ char *former = "hello"; int len1,len2; printf("%sn",former); char *after = base64_encode(former, 5,&len1); printf("%d %sn",len1,after); former = base64_decode(after, len1,&len2); printf("%d %sn",len2,former); }
逆向识别后面一块说,先来看看Base32吧
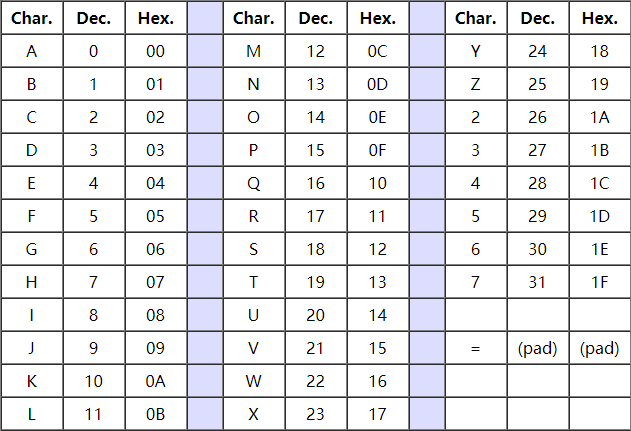
Base32 编码规则 Base32这种数据编码机制,主要用来把二进制数据编码成可见的字符串,其编码规则是:任意给定一个二进制数据,以5个位(bit)为一组进行切分(base64以6个位(bit)为一组),对切分而成的每个组进行编码得到1个可见字符。Base32编码表字符集中的字符总数为25=32个,这也是Base32名字的由来。
下面是Base32的table
C代码实现 #include <stdio.h> #include <string.h> #include <stdlib.h> //base32 表包含 0~9 以及小写字母 (去除'a','i','l','o'), //共 32 个字符 static const char base32_alphabet[32] = { '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'j', 'k', 'm', 'n', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z', }; /* * 匹配 base32_alphabet */ int find_number(char m) { int i; for(i = 0; i < 32; ++i) { if(m == base32_alphabet[i]) return i; } return -1; } /* * base32 编码 */ char* base32_encode(char *bin_source){ int i; int j = 0; static char str[10]; for(i=0;i<strlen(bin_source);++i){ if((i+1)%5==0){ j++; int num = (bin_source[i]-'0')+(bin_source[i-1]-'0')*2\ +(bin_source[i-2]-'0')*2*2+(bin_source[i-3]-'0')*2*2*2\ +(bin_source[i-4]-'0')*2*2*2*2; str[j-1] = base32_alphabet[num]; } } return str; } /* * base32 解码 */ int* base32_decode(char *str_source){ int i,j; static int dec[50]; int count=0; for(i=0;i<strlen(str_source);++i){ for(j=5-1;j>=0;--j){ count++; //位运算十进制转二进制 dec[count-1] = find_number(str_source[i])>>(j%5)&1; } } return dec; }
逆向分析 前面写了这么多,终于到重头戏逆向了,先简略概括一下基本运算法则吧
base64编码是用64(2的6次方)个ASCII字符来表示256(2的8次方)个ASCII字符,也就是三位二进制数组经过编码后变为四位的ASCII字符显示,长度比原来增加1/3。
同样,base32就是用32(2的5次方)个特定ASCII码来表示256个ASCII码。所以,5个ASCII字符经过base32编码后会变为8个字符(公约数为40),长度增加3/5.不足8n用“=”补足。
base16就是用16(2的4次方)个特定ASCII码表示256个ASCII字符。1个ASCII字符经过base16编码后会变为2个字符,长度增加一倍。不足2n用“=”补足
Base32在比赛中常见到,就拿Base32的题来举例了
两道题的完整wp都在博客里 ,(https://kabeor.cn/2017%E7%AC%AC%E4%BA%8C%E5%B1%8A%E5%B9%BF%E4%B8%9C%E7%9C%81%E5%BC%BA%E7%BD%91%E6%9D%AF%E7%BA%BF%E4%B8%8A%E8%B5%9BNonstandard/ ,https://kabeor.cn/2018%E5%B7%85%E5%B3%B0%E6%9E%81%E5%AE%A2%E7%BD%91%E7%BB%9C%E5%AE%89%E5%85%A8%E6%8A%80%E8%83%BD%E6%8C%91%E6%88%98%E8%B5%9B%20RE(1)%20Simple%20Base-N/ )
提取重点部分来说
1. 数据 Base系列的补位“=”算是最明显的提示标志了,搜索字符串时见到类似下图就可以考虑Base了
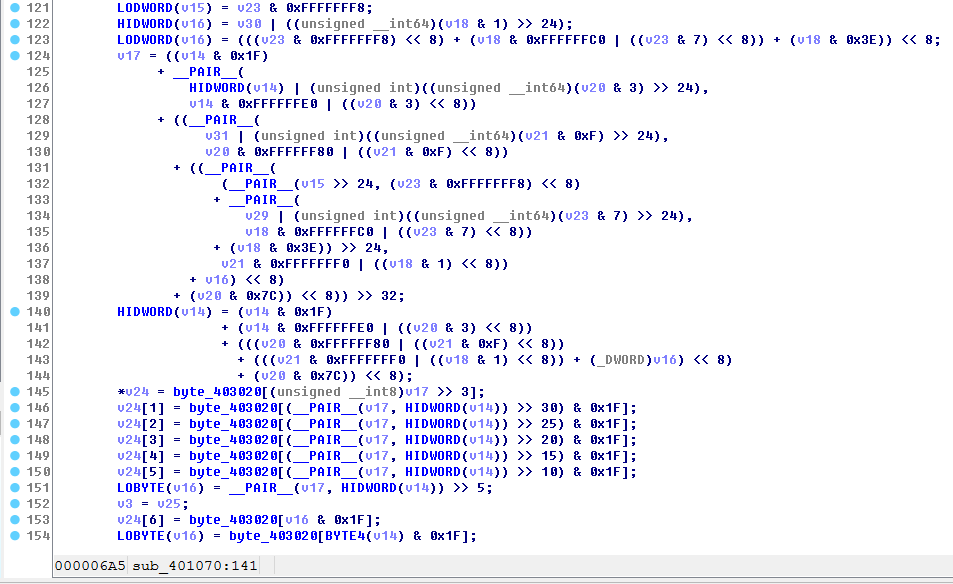
2. 反汇编伪代码 IDA F5,看到大量移位,如图
v14 = v13; HIDWORD(v15) = v19; LODWORD(v15) = v23 & 0xFFFFFFF8; HIDWORD(v16) = v30 | ((unsigned __int64)(v18 & 1) >> 24); LODWORD(v16) = (((v23 & 0xFFFFFFF8) << 8) + (v18 & 0xFFFFFFC0 | ((v23 & 7) << 8)) + (v18 & 0x3E)) << 8; v17 = ((v14 & 0x1F) + __PAIR__( HIDWORD(v14) | (unsigned int)((unsigned __int64)(v20 & 3) >> 24), v14 & 0xFFFFFFE0 | ((v20 & 3) << 8)) + ((__PAIR__( v31 | (unsigned int)((unsigned __int64)(v21 & 0xF) >> 24), v20 & 0xFFFFFF80 | ((v21 & 0xF) << 8)) + ((__PAIR__( (__PAIR__(v15 >> 24, (v23 & 0xFFFFFFF8) << 8) + __PAIR__( v29 | (unsigned int)((unsigned __int64)(v23 & 7) >> 24), v18 & 0xFFFFFFC0 | ((v23 & 7) << 8)) + (v18 & 0x3E)) >> 24, v21 & 0xFFFFFFF0 | ((v18 & 1) << 8)) + v16) << 8) + (v20 & 0x7C)) << 8)) >> 32; HIDWORD(v14) = (v14 & 0x1F) + (v14 & 0xFFFFFFE0 | ((v20 & 3) << 8)) + (((v20 & 0xFFFFFF80 | ((v21 & 0xF) << 8)) + (((v21 & 0xFFFFFFF0 | ((v18 & 1) << 8)) + (_DWORD)v16) << 8) + (v20 & 0x7C)) << 8); *v24 = byte_403020[(unsigned __int8)v17 >> 3]; v24[1] = byte_403020[(__PAIR__(v17, HIDWORD(v14)) >> 30) & 0x1F]; v24[2] = byte_403020[(__PAIR__(v17, HIDWORD(v14)) >> 25) & 0x1F]; v24[3] = byte_403020[(__PAIR__(v17, HIDWORD(v14)) >> 20) & 0x1F]; v24[4] = byte_403020[(__PAIR__(v17, HIDWORD(v14)) >> 15) & 0x1F]; v24[5] = byte_403020[(__PAIR__(v17, HIDWORD(v14)) >> 10) & 0x1F]; LOBYTE(v16) = __PAIR__(v17, HIDWORD(v14)) >> 5; v3 = v25; v24[6] = byte_403020[v16 & 0x1F]; LOBYTE(v16) = byte_403020[BYTE4(v14) & 0x1F]; v2 = v32; v24[7] = v16; v24 += 8; } while ( v8 < v25 ); result = v28; } if ( v22 > 0 ) memset(&result[v26], 61u, v22); *(&v28[v26] + v22) = 0; result = v28; } return result; }
核心算法提取出来了,我们看到了
LODWORD(v16) = (((v23 & 0xFFFFFFF8) << 8) + (v18 & 0xFFFFFFC0 | ((v23 & 7) << 8)) + (v18 & 0x3E)) << 8;
和
v24[1] = byte_403020[(__PAIR__(v17, HIDWORD(v14)) >> 30) & 0x1F]; v24[2] = byte_403020[(__PAIR__(v17, HIDWORD(v14)) >> 25) & 0x1F]; v24[3] = byte_403020[(__PAIR__(v17, HIDWORD(v14)) >> 20) & 0x1F]; v24[4] = byte_403020[(__PAIR__(v17, HIDWORD(v14)) >> 15) & 0x1F]; v24[5] = byte_403020[(__PAIR__(v17, HIDWORD(v14)) >> 10) & 0x1F];
每次取5个比特,分别赋给8个值,每个值5个位 ,显然的base32
3. table table一般在核心算法的上一层函数,数据段也有所显现,当然table也许会被加密或者替换,但都是类似异或,转换进制,运算,奇偶位之类的,照着写脚本就好,
像下图这样就是经过了字母倒序,奇数小写偶数大写,尾部追加得到table
解密脚本 Python3脚本
s = "密文" table = "表" def find(x): if(x=='='): return 0 return table.index(x) for i in range(len(s)//8): p = s[i*8:i*8+8] t = 0 for j in p: t = t<<5 t += find(j) for j in range(5): print(chr((t&0xff00000000)>>32), end='') t = t<<8
魔改Base 经过上面的分析也就可以知道Base中可变的几个部分
CTF中常见的变化位置有下面几个
table
这个上面提到了。。
移位数据变化
从例子可以看出决定了题中Base-N的N是多少的是移位个数和移位距离
组合
很多题都会通过组合加密的方式来提升题目难度,Base中应该就是加密密文和table了
总结 差不多就是这样了,Base-N相对来说只要熟悉模板就能很快识别了。
希望自己能坚持下去,分析不同的算法:)