第15章 对抗反汇编
1. 何谓对抗反汇编技术
实现对抗反汇编时,恶意代码编写者会创建一段代码序列,欺骗反汇编器,让反汇编器展示与真正执行的代码不同的指令列表。
2. 挫败反汇编算法
对抗反汇编技术是基于反汇编算法的天生漏洞而产生的。为了清晰地显示反汇编代码,反汇编器在事前都会做某种特定的假设。一旦这种假设不成立,恶意代码作者就有机会欺骗分析人员。
反汇编算法可以分为两种:线性反汇编算法和面向代码流的反汇编算法。其中线性反汇编算法容易实现,但也易出错。
线性反汇编
线性反汇编策略是遍历一个代码段,一次一条指令的线性反汇编,从不偏离。反汇编器使用的这个基本策略已经被反汇编写作教程采用,并且被调试器广泛使用。线性反汇编用已经反汇编的指!令大小来决定下一个要反汇编的字节,而不考虑代码流的控制指令
利用反汇编库libdisasm,C实现基于线性反汇编算法的反汇编器
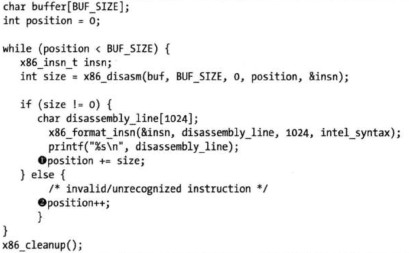
本例中,名为 buffer的数据缓冲区包含需要反汇编的指令。函数x86 disasm将会用刚刚反汇编过的具体指令填充一个数据结构,然后返回这个指令的大小。如果反汇编是一条合法指令,这个循环会用size值递增 position变量(如1所示),否则递增1(如2所示)
这个代码片段中的许多指令拥有多个字节,恶意代码编写者利用线性反汇编算法的关键方法是植入能够组成多字节指令机器码的数据字节。例如,标准的本地ca11指令有5个字节,以机器码0xE8开头。如果16字节数据组成一个以值0xE8结尾的开关表,那么当反汇编器碰到Call指令的机器码时会将接下来的4个字节当作操作数对待,而不是当作下一个函数的开头。
线性反汇编算法不能区分代码与数据,因此最容易被恶意代码挫败。
面向代码流的反汇编
面向代码流的反汇编与线性反汇编的主要不同在于,面向代码流的反汇编器并不盲目地反汇编整个缓冲区,也不假设代码段中仅包含指令而不包含数据。相反,它会检查每一条指令,然后建立一个需要反汇编的地址列表。
如果IDAPro产生了不正确的反汇编代码,你可以利用键盘上的C键或D键,手动将指令转换成数据或者将数据转换成指令。步骤如下:
- 按C键可以将光标位置的数据转换成代码。
- 按D键可以将光标位置的代码转换成数据。
3. 对抗反汇编技术
恶意代码最常见的对抗反汇编技术的主要方法是利用反汇编器选择算法和假设算法的漏洞,使反汇编器产生错误的反汇编代码。
相同目标的跳转指令
恶意代码中最常见的对抗反汇编技术是使用指向同一目的地址的两个连续条件跳转指令。
如果jz1oc_512指令之后是jnz loc_512,则总是跳转到loc_512。jz指令与jnz指令的结合,在效果上等于无条件跳转指令jmp,因为反汇编器每次只反汇编一条指令,所以并不会意识到这种情况。当反汇编器遇到jnz指令时,依然会反汇编这个指令的false分支,尽管事实上这个分支永远不会执行。
固定条件的跳转指令
在恶意代码中,另一种常见的对抗反汇编技术是由跳转条件总是相同的一条跳转指令构成的。

注意这段代码以xor eax,eax指令开头,这条指令的作用是将EAX寄存器置0,与此同时它也会设置标志寄存器的zero标志。下一条指令是条件跳转指令,如果标志寄存器zero标志被置位,它就会执行跳转。事实上,这根本不是条件跳转,因为在程序的这个位置,我们可以保证zero标志总是被置位的。
xor指令与相邻jz指令的永假关系
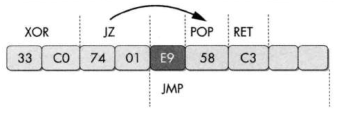
无效的反汇编指令
前面讨论的简单的对抗反汇编技术是巧妙地在条件跳转指令之后放一个字节,这种技术的思路是,从这个字节开始反汇编,阻止其后真正的指令被反汇编,因为插入的字节是一个多字节指令的机器码。我们称这样的字节为流氓字节,因为它不属于程序的一部分,只是用在代码段迷感反汇编器。
但是,如果流氓字节不能被忽略,如果它是合法指令的一部分,且在运行时能够被正确执行怎么办?这里,我们碰到一个棘手的问题,所有给定字节都是多字节指令的一部分,而且它们都能够被执行。目前业内没有一个反汇编器能够将单个字节表示为两条指令的组成部分,然而处理器并没有这种限制。
内部跳转的jmp指令

当试图表达这个反汇编序列时,会十分困惑,因为如果将字节FF作为jmp指令的一部分,那么就不能作为inc eax指令的开头来进行显示。字节FF同时作为两条实际运行指令的一部分,而现代反汇编器并没有办法表达这种情况。这4个字节序列首先递增EAX,然后递减EAX。实际上,这是一个复杂的NOP序列,几乎可以插入程序的任何位置,从而破坏有效的反汇编链。为了解决这个问题,恶意代码分析人员常使用IDC或者IDAPython脚本,调用PatchByte函数,用NOP指令序列替换这个字节序列,另一种办法是使用D键将这样的字符序列全部转换成数据,让这4个字节之后的反汇编恢复正常。
多层内部调转序列
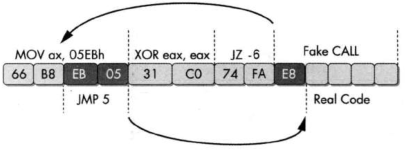
在字节序列中,第一条指令是4字节的mov指令,其最后2个字节被高亮显示,因为它既是mov指令的一部分,同时也作为随后运行的一条指令。第一条指令会用数据填充AX寄存器。第二条指令xor会归零这个寄存器,且将标志寄存器zero置0。第三条指令是一个条件跳转指令,当标志寄存器zero标志置位时,它执行跳转。实际上它不是一个条件跳转,因为它的前一条指令总是设置zero标志。反汇编器会反汇编紧跟jz的指令,该指令以字节0xE8开头,0xE8是一个5字节call指令的机器码。然而这条以0xE8开头的指令实际上永远不会执行。
在这种情况下,反汇编器不能正确反汇编jz指令目标,因为这个字节已经被正确表达为mov指令的一部分。jz指令指向的代码总会被执行,因为jz指令运行时,zero标志总是被置位。指令z跳转到4字节的mov指令中间。mov指令的最后两个字节是存放在寄存器中的操作数。当单独反汇编或者运行这个操作数时,它又会组成一个jmp指令,这条jmp指令会从指令末尾向前跳转5个字节。
IDAPython将字节换成NOP
def NopBytes(start,length): |
用IDA PRO对指令进行NOP替换
如下脚本的作用是创建一个热键ALT+N,一旦脚本运行,无论用户何时按下ALT+N组合键,IDAPro都会使用NOP指令替换当前光标位置处的字节。它也能简单地将光标移到下一条指令处,从而使替换大块代码变得更容易。
import idaapi |
4. 混淆控制流图
函数指针问题
在C语言程序中刻意使用函数指针,这可以大大降低反汇编器自动推导出程序流的信息量。如果在汇编语言中刻意使用函数指针或者在源码中构造不标准的函数指针格式,会导致在没有动态分析的前提下很难进行逆向工程。
在IDA Pro中添加代码的交叉引用
使用IDC中名为AddCodeXref的函数。它有三个参数:交叉引用来源的位置、交叉引用指向的位置,以及流的类型。这个函数可以支持多个不同的流类型,但最常用的是普通call指令类型fl_CF,或是跳转指令的类型fl_JF。
滥用返回指针
在程序中,call指令和jmp指令并不是唯一转换控制流的指令。与call指令对应的指令是retn(也被表示为ret)。call指令与jmp指令功能类似,不同的是它将函数返回地址压入到栈中,返回点是紧随call指令的一个内存地址。
call指令等同于jmp指令加push指令,retn指令等同于jmp指令加pop指令。retn指令首先从栈顶弹出一个值(返回值地址),然后跳转到这个值所表示的地址处。retn通常被用来返回一个函数调用,但由于体系结构的限制,它不能用于一般的执行控制流。
当retn指令不以函数调用返回的方式被使用时,这种技术的最显著结果是反汇编器不能显示代码中任何要跳转的交又引用目标。另一个显著的结果是反汇编器会提前结束这个函数。
滥用结构化异常处理
结构化异常处理(SEH)提供一种控制流的方法,该方法不能被反汇编器采用,但可以用来欺骗反汇编器。SEH是×86体系结构的一种功能,旨在为程序提供一种智能处理错误条件的方法。编程语言例如C++,Ada等,严重依赖异常处理,并且在x86系统上编译时会自动翻译成SEH。
异常触发可能有多种原因,例如访问一个无效内存区域、除零等。也可以调用函数RaiseException产生额外的软件异常。
SEH链是一个函数列表,设计它的目的是处理线程中的异常。列表中的每个函数,要么处理异常,要么将异常传递到列表中的下一个函数。如果一个异常总是被传递到最后一个异常处理函数处,就会被认为是一个不能处理的异常。这种情况下,最后一个异常处理函数会负责弹出一个熟悉的消息对话框,通知用户“an unhandled exception has occurred”。在大多数进程中,异常是有规律地产生的,但在到达最后状态(使程序崩溃并通知用户)之前,异常都会被静悄悄的处理。
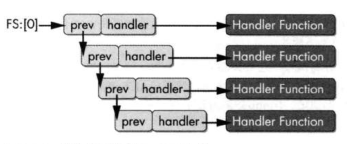
为了查找SEH链,操作系统会检查FS段寄存器。这个寄存器包含一个段选择子,使用段选择子可以得到线程环境块(TEB)。TEB中第一个数据结构是线程信息块(TIB)。TIB中的第一个元素(即TIB的第一个字节)就是SEH链的指针。SEH链是一个简单的8字节数据结构链表,这个8字节数据结构叫作EXCEPTION_REGISTRATION记录。
struct_EXCEPTION_RECISTRATION{ |
EXCEPTION_REGISTRATION记录的第一个元素是一个指向前一个记录的指针。第二个元素则是一个指向异常处理函数的指针。
从概念上讲,这个链表以栈的方式进行操作。第一个调用的是最后一个加入链表的记录。由于子进程的调用与嵌套的异常处理块的原因,SEH链的增长和缩小等同于程序中异常处理层的改变,所以SEH记录总是建在栈上。
利用SEH实现变相控制程序流,并不需要在意当前异常处理链有多少个记录,只需要了解怎么将自己的异常处理添加到链表的头部
 。
。
为了将一条记录添加到这个链中,我们需要在栈上构造一条新记录。因为记录结构由两个DWORD变量组成,所以使用两个push指令来完成。栈是向上增长的,所以第一个push进栈的是异常处理函数指针,第二个push进栈的是下一条记录的指针。当添加一条记录到链表的头部时,下一条记录需要完成的异常处理是当前的栈项,它由fs[e]指针给出。下面是实现这一功能的代码:
push ExceptionHandler |
异常发生时,将首先调用函数ExceptionHandler。这个动作会受到微软的软件数据执行保护机制(软件DEP,也被称为SafeSEH)的限制。
软件DEP是一项安全功能,它的目的是阻止程序运行过程中添加第三方的异常处理。对于硬编码的代码,有几种方法能够绕过这种技术,例如使用支持SafeSEH指令的汇编器。另外,使用微软的C编译器也能达到此目的,添加/SAFESEH:NO到链接器命令行,就可使这种限制无效。
当调用ExceptionHandler函数时,栈将被大幅改变。幸运的是,要达到我们的目的,没必要检查添加到栈中的所有数据。我们必须知道怎么返回异常发生前的栈位置。回想一下,我们的目的是混淆控制流且使程序不能正确处理异常。
当异常处理被调用时,操作系统添加了其他的SEH处理。为了让程序恢复正常操作,不仅要将我们的异常处理从异常处理链中断开,还要将系统添加的异常处理从异常处理链中断开。因此,我们需要从esp+8处而不是esp处取出原始的栈指针。
mov esp,[esp+8] |
5. 挫败栈帧分析
为了解决栈帧的轻微调整(用栈帧分析的固有易犯错特性偶尔会导致这种情况发生),在IDA Pro中,将光标放到某个特定反汇编行上,然后通过按ALT+K组合键,输入调整的栈指针值。


